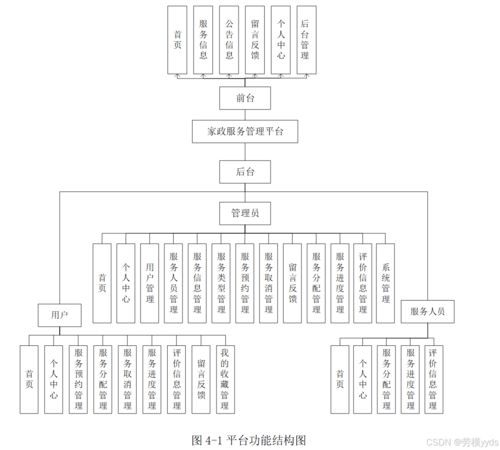
網(wǎng)絡(luò)工程師(簡(jiǎn)稱網(wǎng)工)作為信息技術(shù)領(lǐng)域的重要角色,在信息系統(tǒng)運(yùn)行維護(hù)服務(wù)中發(fā)揮著不可或缺的作用。他們的工作內(nèi)容涵蓋網(wǎng)絡(luò)系統(tǒng)的設(shè)計(jì)、實(shí)施、監(jiān)控與優(yōu)化,確保企業(yè)信息系統(tǒng)穩(wěn)定、安全、高效運(yùn)行。以下是網(wǎng)絡(luò)工程師在信息系統(tǒng)運(yùn)行維護(hù)服務(wù)中的主要職責(zé):
網(wǎng)絡(luò)工程師負(fù)責(zé)網(wǎng)絡(luò)基礎(chǔ)設(shè)施的日常運(yùn)維。這包括對(duì)路由器、交換機(jī)、防火墻等網(wǎng)絡(luò)設(shè)備進(jìn)行配置與管理,監(jiān)控網(wǎng)絡(luò)性能指標(biāo)如帶寬利用率、延遲和丟包率,并及時(shí)處理網(wǎng)絡(luò)故障。例如,當(dāng)企業(yè)網(wǎng)絡(luò)出現(xiàn)中斷時(shí),網(wǎng)工會(huì)迅速診斷問題,可能是硬件故障或配置錯(cuò)誤,并采取恢復(fù)措施,確保業(yè)務(wù)連續(xù)性。
網(wǎng)絡(luò)工程師參與信息安全防護(hù)。在運(yùn)行維護(hù)服務(wù)中,他們需實(shí)施安全策略,如配置訪問控制列表(ACL)、部署入侵檢測(cè)系統(tǒng)(IDS)和防火墻規(guī)則,以防范網(wǎng)絡(luò)攻擊和數(shù)據(jù)泄露。定期進(jìn)行漏洞掃描和補(bǔ)丁管理也是關(guān)鍵任務(wù),幫助系統(tǒng)抵御外部威脅。
第三,網(wǎng)絡(luò)工程師負(fù)責(zé)網(wǎng)絡(luò)優(yōu)化與升級(jí)。隨著業(yè)務(wù)增長(zhǎng),信息系統(tǒng)需求不斷變化,網(wǎng)工需要分析網(wǎng)絡(luò)流量模式,優(yōu)化網(wǎng)絡(luò)架構(gòu),提升性能。這可能涉及升級(jí)設(shè)備、引入新技術(shù)如SD-WAN(軟件定義廣域網(wǎng))或云集成,以適應(yīng)數(shù)字化轉(zhuǎn)型。
第四,在信息系統(tǒng)運(yùn)行維護(hù)中,網(wǎng)絡(luò)工程師還需提供技術(shù)支持與文檔管理。他們協(xié)助用戶解決網(wǎng)絡(luò)相關(guān)問題,編寫運(yùn)維手冊(cè)和故障處理流程,確保知識(shí)傳承和合規(guī)性。參與備份與災(zāi)難恢復(fù)計(jì)劃,確保系統(tǒng)在突發(fā)事件下快速恢復(fù)。
網(wǎng)絡(luò)工程師在信息系統(tǒng)運(yùn)行維護(hù)服務(wù)中扮演著多面手角色,其工作不僅保障網(wǎng)絡(luò)穩(wěn)定,還推動(dòng)企業(yè)信息化進(jìn)程。對(duì)于依賴信息系統(tǒng)的組織而言,擁有一支專業(yè)的網(wǎng)工團(tuán)隊(duì)是提升運(yùn)營(yíng)效率和降低風(fēng)險(xiǎn)的核心要素。