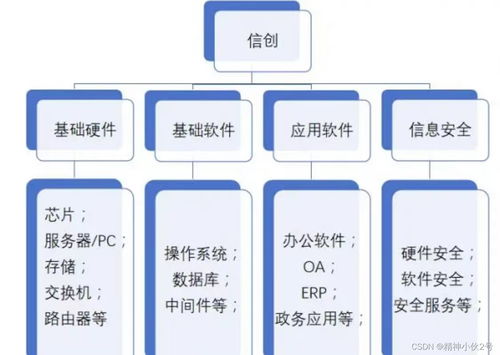
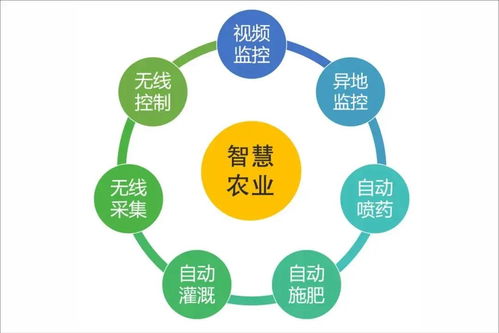
為深入貫徹國家關于網絡安全工作的重要指示精神,落實屬地管理責任,保定市下轄多縣(市、區)網信辦積極行動,聯合相關職能部門,聚焦轄區內關鍵信息基礎設施和重要信息系統,集中組織開展了網絡安全專項檢查,重點圍繞信息系統運行維護服務環節,旨在全面排查風險隱患,提升網絡安全防護能力,為地方經濟社會發展和人民群眾利益保駕護航。
本次專項檢查行動覆蓋范圍廣、針對性強。各縣(市、區)網信辦結合本地實際,制定了詳細的檢查方案,明確檢查對象、內容、標準與流程。檢查對象主要涵蓋政府機關、事業單位、重點企業等單位運行的核心業務系統、門戶網站、數據平臺等。檢查重點聚焦于信息系統運行維護服務的規范性、安全性與有效性,具體包括:
- 制度與責任落實: 檢查相關單位是否建立健全網絡安全管理制度,是否明確運行維護服務的安全責任部門和人員,是否簽訂包含安全條款的服務協議,以及安全責任是否清晰、可追溯。
- 運維過程安全管理: 核查日常運維操作是否規范,訪問控制是否嚴格(如權限管理、身份認證、操作審計),漏洞掃描與修復是否及時,數據備份與恢復機制是否完備,對運維服務商(如有)的監督與管理是否到位。
- 應急響應與處置能力: 評估網絡安全事件應急預案的可行性與有效性,檢查應急演練開展情況,以及面對安全威脅時的監測、預警、報告和處置流程是否暢通、高效。
- 人員安全意識與培訓: 了解運維相關人員的安全意識水平,檢查是否定期開展網絡安全法律法規、政策標準及技能培訓,是否具備基本的安全風險防范和處置能力。
檢查過程中,網信辦工作人員通過查閱文檔、現場詢問、技術檢測等多種方式,深入了解各單位信息系統運行維護服務的實際情況。對于發現的部分單位存在的管理制度不完善、運維操作記錄不全、安全防護措施更新不及時、第三方服務管理存在薄弱環節等問題,檢查人員現場提出了明確的整改意見,要求相關單位限期整改,并將在后續進行“回頭看”,確保問題整改到位、不留死角。
此次專項檢查不僅是一次全面的安全“體檢”,更是一次深入的宣傳與督導。各縣(市、區)網信辦借此機會,向被檢查單位進一步強調了網絡安全的重要性,特別是運行維護服務作為保障信息系統持續穩定安全運行的關鍵環節,絕不能有絲毫松懈。要求各單位切實承擔起網絡安全主體責任,將安全要求融入運維服務的全過程,選擇合規、可信的運維服務提供商,加強內部安全管理,定期開展自查自糾,共同構筑堅固的網絡安全屏障。
下一步,保定市各相關縣(市、區)網信辦將持續加強網絡安全常態化監管,完善跨部門協同聯動機制,加大網絡安全法律法規宣傳普及力度,提升全社會網絡安全意識。將根據此次專項檢查的結果,共性問題,研究制定更具針對性的指導意見或措施,推動本地區信息系統運行維護服務向更規范、更安全、更高效的方向發展,為數字保定建設提供堅實可靠的網絡安全保障。